Today we’ll talk about multiple instances of one (micro)service synchronization.
Imagine that we have one storage that has one binary file per data type, a queue of data, containing messages with specified data types and a pool of worker services that get messages with specific data type from the queue and write them to the corresponding binary storage file.
Let’s visualize this with a picture.
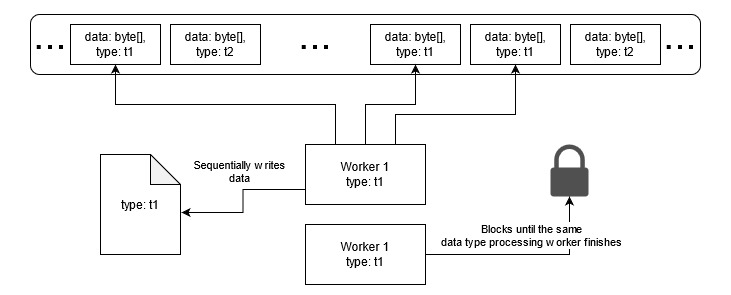
Each worker gets the data type it needs to read from queue and write to the storage as an input parameter. There can be cases when several workers are run with the same data type parameter.
The storage only supports sequential single-threaded writes to ensure the binary data integrity. Therefore when we have to increase the number of workers, we need to ensure that there will never be a situation when two workers get the same data type messages from the queue and start writing them to the storage in overlapped streams corrupting each other’s data. If the processing occurs on different data types it’s completely OK since different data types go to different physical binary files.
What we have here is a classic thread synchronization task and the synchronization primitive we require is mutex. But when workers are physically located on different machines (Azure Batch or k8s nodes, for instance) there is no built-in way to get a mutex. Let’s create one then.
Actually, what we need to build is a shared per-data type mutex pool. What shared resource do all the workers use in our case? It’s the input message queue itself. Let’s say that the storage we are using to store the input messages is MongoDb. Not exactly a canonical usage of a database, but I promise that it’s going to be interesting in a minute so stay with me.
MongoDb guarantees that any operation on a single document is atomic. This, combined with a unique index constraint, gives us the following solution. We can create a separate collection with unique index on data type property and try to insert a document for each data type on the worker start. If the insert succeeds – we can continue working – no one else locked the data file yet. When work is done we simply delete the “lock” document. If we fail to insert a document, then we need to wait and try to insert it again in some kind of a loop that eventually breaks when the document insert succeeds and worker can proceed with its business.
The actual straightforward implementation of the described solution is quite simple, but let’s make it a bit more neat and fun.
When talking about locking primitives, .net has a synchronous blocking and an asynchronous non-blocking ones. Since we don’t want to block the thread that is trying to get the lock we are going with an asynchronous one. As I said before, there is no built-in distributed mutex (please correct me if I’m wrong!) but we can build something that resembles one:
var mutex = new MongoMutex("t1"); // assuming we are locking on "t1" data type
await mutex.WaitAsync();
try
{
// do some data writing work here
}
finally
{
await mutex.ReleaseAsync();
}Let’s see how MongoMutex.WaitAsync() method is implemented.
public async Task WaitAsync()
{
bool isInsertSuccess = await TryInsertMutexDocument();
if (isInsertSuccess)
{
return;
}
await this;
}
private async Task TryInsertMutexDocument()
{
var itemToInsert = MongoMutexDocument.Create(_dataType);
return await MongoHelper.TryConcurrentInsert(
async () =>
{
await _collection.InsertOneAsync(itemToInsert);
_isLockTaken = true;
},
() => _onConcurrentInsertConflict(itemToInsert)
);
}First, we are trying to insert a mutex document and if we are succeeded, we simply return. The insert uses MongoHelper.TryConcurrentInsert method that simply executes the specified insert logic and if it encounters unique index constraint violation (which means that the mutex document for the same data type already exists) it executes some action.
The success branch is pretty much self-explanatory, but if we fail to insert right away, the magical await this happens. This expression tells us that the MongoMutex class is actually an awaitable. But wait, how do we make it an awaitable?
To answer this question let’s go to the (draft) version of a C# language specification, section 7.7.7.1 Awaitable expressions:
The task of an
awaitexpression is required to beawaitable. An expressiontisawaitableif one of the following holds:tis of compile time typedynamic *t*has an accessible instance or extension method calledGetAwaiterwith no parameters and no type parameters, and a return typeAfor which all of the following hold:Aimplements the interfaceRuntime.CompilerServices.INotifyCompletion(hereafter known asINotifyCompletionfor brevity)Ahas an accessible, readable instance propertyIsCompletedof typebool *A*has an accessible instance methodGetResultwith no parameters and no type parameters
MongoMutex is obviously not of type dynamic. Then the second part of the spec should somehow be satisfied, and indeed it is is the following way.
private TaskAwaiter GetAwaiter()
{
_awaiterPollingTimer.Elapsed += async (sender, args) =>
{
try
{
var insertSuccess = await TryInsertMutexDocument();
if (insertSuccess)
{
// mutex document successfully inserted
_completion.SetResult(true);
}
else
{
// mutex document already exists - retry
_awaiterPollingTimer.Start();
}
}
catch (Exception ex)
{
// something went wrong
_completion.SetException(ex);
}
};
_awaiterPollingTimer.Start();
return _completion.Task.GetAwaiter();
}Now, what’s going on here? Recall that if we fail to insert a document we call await this. This internally calls GetAwaiter() method, which in turn hooks up the insert retry on an internal timer. To avoid creating another type that implements INotifyCompletion, has an IsCompleted property and a GetResult method, we simply return a TaskAwaiter<bool> instance that already has all that stuff. And that instance we obtain from internal TaskCompletionSource<bool>!
Using this technique you can make virtually any type awaitable. Sometimes though using TaskCompletionSource<TResult> should be avoided. In that case we can simply create a custom awaiter class that conforms to the spec. The perfect description of a more complex scenario is given in the Stephen Toub’s blog post on this topic : https://devblogs.microsoft.com/pfxteam/await-anything/.
With locking logic generalized as a mutex-like class, the consuming code looks a lot more clean and readable, then the possible straightforward implementation. On the other hand, the described solution can be worse in terms of allocations and performance than the possible specialized locking implementation, but I’ll leave the profiling and benchmarking part as an exercise to the reader.