Now, that’s the solution which is as much interesting itself as the way we came to it. Let’s add some context.
We are the core system that stores the crucial business-related data. Our dataset is relational and big, and by big I mean several billion rows big. We use PostgreSQL and host our databases on-premise, so our skies are cloudless, our infra team is as busy as it could possibly be, and maybe a bit more. We need to store around 5 TB of data in out database with plans on growing it twofold in a year. Our workload is 15% of inserts / updates and 75% of reads. Last point is that for the sake of rapid backup and restore, one physical database server can hold at most 500GB of data.
The task at hand is to develop a storage solution that would be highly scalable in terms of data storage, availability and throughput.
Well, there are two ways of achieving this and both involve dividing the whole data set between multiple server instances or, in another words – sharding. I’ll overview both of them but let’s first discuss which options we have for sharding the data in modern databases.
Sharding the world
Ready
Let me do a quick recap of how sharding works.
Sharding is a process of splitting one large, structured, contiguous set of some objects (I don’t call them rows since we can shard practically any dataset) into smaller parts with the same structure and putting these smaller partial sets on different physical servers.
The idea is really simple. First – we select one property of an atomic object in a set and call it a shard key. The value of a shard key will determine the location of the data.
When we need to store some data – we somehow transform the value of the shard key to determine its physical location i.e. which server the data should be placed on.
To read the stored data from server it was routed to we need to specify the shard key again to transform it and get relevant physical location to read required data from.
So given a set of keys and some transformation we can distribute data between servers.
Set
Now the crucial part in good sharding solution is data distribution. When we have several servers with equal characteristics available, we don’t want the data to go to a single one – that would void all purpose of sharding. To achieve a maximum throughput in sharded database we need the data to be evenly distributed between servers. There are some cases when we purposefully don’t want an even distribution – for example when the servers we are putting data to are not equal in terms of computing power, or spatial distribution but that’s rather exotic case and we won’t be using it for now.
So we need an even distribution. How do we get that? The trick lies in shard key transformation.
We need a transformation that maps the input values to the output values as evenly as possible over its output range. Luckily we have a set of mathematical functions with exactly that properties – hash functions.
The algorithm here is simple. We get a shard key, feed it to the hash function and get some value, let’s say an unsigned 64-bit integer value. For the same input values an output value will always be the same, while for the different values we may or may not get different hash values. When we get the same (duplicate) hash value for different input values – we call it a collision. Good hash functions should minimize duplication of output values i.e. have a minimal collision rate.
Let’s put this theory into action.
Go
Say we need to split one dataset into 16 parts and put each part to a distinct server in a cluster of 16. We get the value of a shard key of each object in a set, then compute its hash and divide it modulo the number of servers we have thus getting the offset in server address array, get the server at that offset, route data to that server and save it there.
There are three ways of performing this.
- Manual – we just do all the calculations and routing by ourselves. We also need to configure the cluster, add the configuration storage, where we describe all the sharded datasets and shard keys. Then rewrite all the data saving and querying procedures to include routing information, and hope that all goes well.
- Automatic – there are databases that have a single (well, almost single) button “shard the damn thing!”.
- Hybrid – when database server itself is uncapable of “sharding the damn thing” out of the box, we use some standalone plugin solution to shard the data for us.
The are several database servers that have an automatic sharding built in, but most of them are NoSql – Elastic, Cassandra, MongoDB, etc. Unfortunately Postgres is not among them. Well… until the time comes, the way is shut.
As for the hybrid solutions for Postgres – most of them are based on PG FDW technology. FDW or foreign data wrapper is a feature that enables PG server to treat a data on the remote server as part of the particular larger data set an interpret this split data set as a whole one. This technology has its caveats, most of which lie in a field of configuration. And it is also very slow. No luck here either.
The only way is through
This leaves us with no choice but to make all the routing by ourselves. That’s where the fun part begins, there will be dragons along the way.
The hash function
The first and foremost thing to choose is our hash function. The common criteria for hash functions are as follows.
- Speed – calculation should be fast on all the input data.
- Distribution – the input values should be mapped to the output values as evenly as possible.
- Collision rate – the number of collisions should be as low as possible.
- Avalanche effect – if an input is changed slightly (for example, flipping a single bit), the output changes significantly (e.g., half the output bits flip).
Last two criteria are vital for cryptographic hash functions and since we are not brewing any cryptography here, when choosing a hash function for sharding purposes we are actually interested in first two criteria.
There is a ton of non-cryptographic hash function comparisons throughout the net. The most canonical test suite is smhasher. The ones that have been considered were.
- DJB2
- SDBM
- LoseLose
- FNV-1 / FNV-1a
- CRC16
- Murmur2/Murmur3
Among mentioned functions Murmur3 is the fastest has the best distribution. There is a new hash algorithm called xxHash, that is said to be faster then Murmur3 without distribution quality decrease, but it’s C# implementation was not available at the time this solution was developed.
Shard resolution algorithm
Now let’s decide how do we calculate the actual shard that the data is routed to – the shard resolution algorithm. We start with the simplest solution and then if it does not satisfy any of our requirements see how do we improve it.
Simplest solution is as simple as a textbook hash table. We take a constant number of physical servers – let’s call them buckets, then we calculate the numeric hash value for our shard key value and divide this value modulo the number of buckets, thus obtaining an offset into the array of servers.
offset = CalculateHash(shard_key) % BucketNumber
server = Servers[offset]Good, but what if after the cluster is configured we need to add or remove a server. The write operations will simply get the new offset and got routed to the new server. But all the read queries will now get the wrong offset and are going to read data from the shard where the data might not be present.
So after the physical shard gets added or removed we need to somehow rearrange the data between the new number of servers – perform a resharding.
The resharding in case of the simple hashtable is painful and scary.
- For each row in each sharded table we recalculate the new offset and move the row to the resulting server.
- Th probability of the new offset being the same as the old one is infinitely low
- We are going to move nearly all the rows.
Given the 5TB of data it’s going to take ages of downtime and very scary data-fixes should anything go wrong. Can we do better?
What if we will initially have a number of servers as some power of 2 add not one node but double the amount of nodes. Let’s see how the resharding process will evolve.
- For each row in each sharded table we recalculate the new offset and move the row to the resulting server.
- Initially we had the number of servers equal to
2^n, the new number is2^(n+1) - The probability of the new offset being the same as the old one is 0.5 so we are going to move half of the rows.
That’s better but works well only for powers of two. Can we still do better than that?
The answer is yes but we will be needing a Ring of Power to do it.
Algorithm I’m talking here about is called Consistent Hashing. Let’s give each server it’s own offset value and put our servers on the ring.
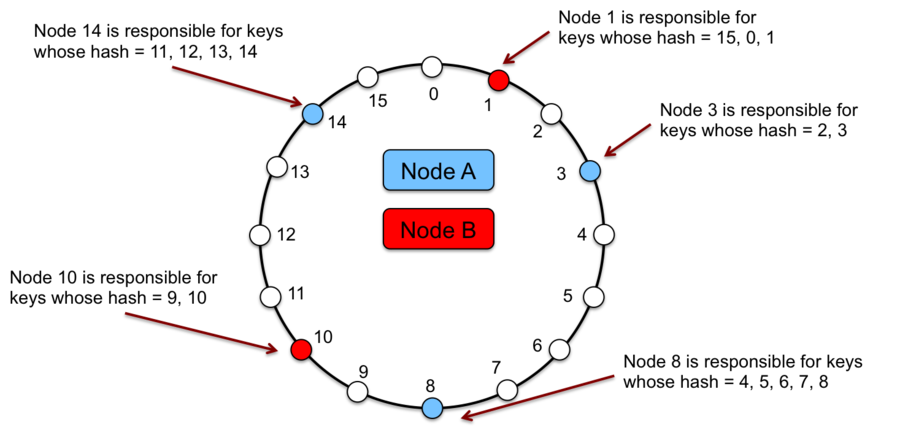
Each server will then have the data that has offset between that node and a previous one. This way when adding a node to the cluster we will need to move data only for servers that are immediately before and after it thus moving only 1/BucketNumber rows.
Now we are talking! But what about data balancing distribution? Well’ that’s not the best solution since there can be cases when the majority of data end up being assigned to one server overloading it.
This problem is easy to solve giving one server more than one random offset making it appear on the ring more than once in random positions.
This algorithm is actually very popular and used in many databases which offer the sharding capabilities out of the box. The examples are DynamoDb, MongoDb, CockroachDb, Cassandra.
There are algorithms even better than that but let’s stop here.
The Consistent Hashing being simple in nature is quite complex in configuration and maintenance so let’s come up with hybrid approach between it and the previous one with powers of 2.
What if we have a constant number of buckets, say 65536 and a number of servers each of which will be responsible for it’s own offset range. Then if we decide to add a server to the cluster we can simply assign a new server some offset range and move only the rows which resolve to that offset.
Cluster configuration
Now let’s decide on how do we configure the cluster. To increase robustness let’s dedicate a cluster node for storing all the configuration – we call it the master node.
We are going to have sharded data and unsharded data. Obviously only the sharded data should be distributed between cluster nodes, all the unsharded (let’s call it solid) data may be put into it’s own dedicated node (or nodes), which we call solid shards. This way we have three types of cluster nodes – master, data and solid. There should be only one master node but we allow any number of data and solid shards.
Now, most databases that provide sharding mechanisms out of the box let you choose which field or group of fields in a particular sharded table will provide a shard key. And that’s the way it was in V1 of the subject solution.
Having sharding configured per table has its advantages. It enables analyzing whether your actual SQL query contains the specified shard key field(s) and rewriting the query on the fly to split it by shards. It also makes it much easier to reason about which data is sharded and how. It also enables you to group single-shard queries to optimize the overall data manipulation.
While having all these advantages per-table sharding adds a configuration overhead and requires reconfiguring for each new table. Moreover, if we don’t analyze each SQL query, which is slow, complicated and thus potentially error-prone, we need to specify the name of the shard key each time we want to perform an operation on a sharded data.
Because we are building our very own home-brew solution we are not obliged to go that way. Let’s see what do we get if we simply throw away the information about which field provides the shard key for a table.
Without the shard key field info we need to specify the shard key value on each shard operation ourselves, but to calculate which shard our data belongs to all the data shard node requests should have it anyway. We now have the ability to add any number of shrded tables without touching any configuration. The overall shard resolution process is now simplified and don’t even need to rewrite the query since we have the shard key right away. Nice, simple, terse.
But we now have a slight complication on our hands. We have no way of checking whether the request that goes to the shard is actually operating on any shrded data. This way we can change the data we were not intended to change if we specify a wrong shard key value. Well, that’s the price of simplicity – the consumer must be extra careful about which requests she makes and to which shards.
What about the solid data? Since we are storing it in a dedicated node we can simply give it a name and each time we need a connection to than node we specify that.
Having decided on sharding algorithm and the configuration processes let’s see how do we store required data in our master node.
Master node
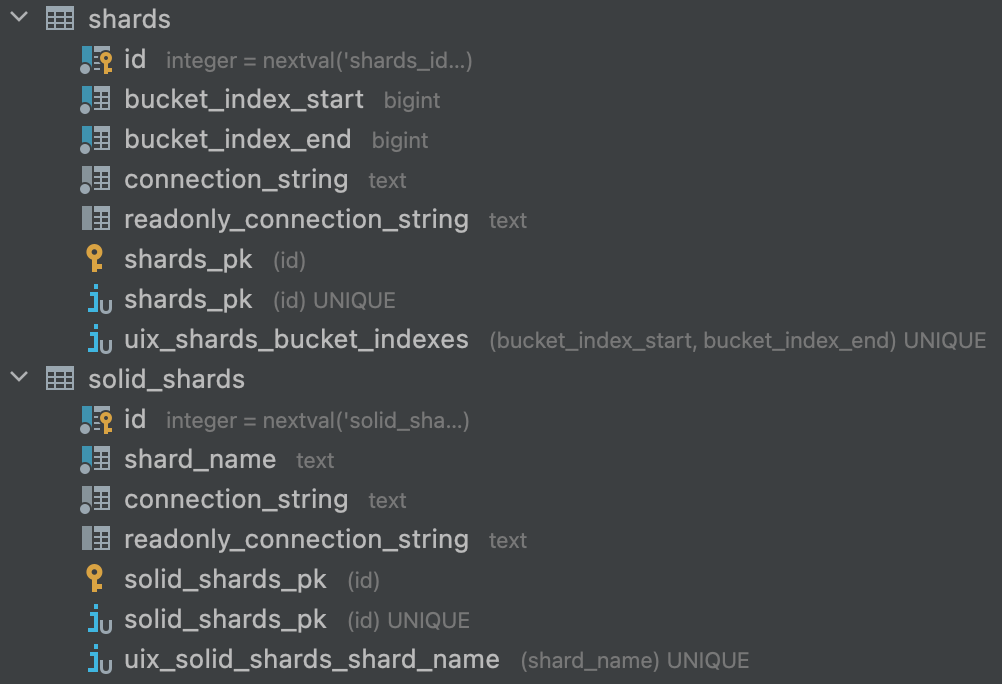
We end up having only two tables. One for data shards and one for the solid ones. Data shard has a range of buckets it’s responsible for and connections strings of a physical node. Solid shard has a name and again the connection strings.
Show me the code!
Now all we need to do is somehow obtain the shard connection. Since we have basically a dictionary with key that can be of any type – all we need to do is specify the value of that key.
var dataShardConnection = await GetShardConnectionAsync(
shardKeyValue,
cancellationToken);Let’s take a closer look at the connection resolution method signature
protected virtual Task<TDbConnection> GetShardConnectionAsync<TShardKeyValue>(
TShardKeyValue shardKeyValue,
CancellationToken token);Why do we need to make a type for a shardKeyValue generic? That’s because we don’t want to cause boxing should the shard key be of a value type. This boxing can result in lots of objects being created in high load scenarios. We will eventually need to turn the key value into a string to calculate hash of that but let’s not add a GC pressure that can otherwise be avoided.
The very similar resolution happens for a solid shard.
var solidShardConnection = await GetSolidShardConnectionAsync(
solidShardName,
cancellationToken);protected virtual Task<TDbConnection> GetSolidShardConnectionAsync(
string solidShardName,
CancellationToken token)Instead of passing a shard key value we simply specify the string shard name.
So what happens when we call the shard resolution method? First we are going to compute the hash value of the specified hash key value and turn it into an offset in our bucket array by dividing it modulo our fixed bucket count of 65536. Note that since new hash functions born and mature every year or so, our solution should offer an abstraction for hash algorithm and bucket calculation to plug any algorithm required for any particular case.
public interface IShardKeyHasher
{
Task<ShardKeyHashBucket> ComputeShardKeyHashAndBucketAsync(string shardKeyValue, CancellationToken token);
}After the offset had been computed we find the bucket range that the value belongs to. We can do it by means of an SQL server that holds the configuration. It’s going to be a simple range query.
SELECT
connection_string,
readonly_connection_string
FROM
shards AS s
WHERE
s.bucket_index_start <= @Offset
AND @Offset <= s.bucket_index_endSince the shards configuration table is not very large the query will have a very small execution time.
Then we simply create an instance of a DbConnection with found connection string, open it and return that to the caller.
Well, that’s basically it but since we are aiming our solution to high load scenarios, we can optimize it a bit.
Three problems in computer science
We have three biggest problems in computer science – off-by-one error, cache invalidation and that we have only one joke and it’s not funny.
Configuration caching
First – since our cluster configuration changes very rarely and can’t be changed without additional resharding anyway, we can cache the whole master shard configuration tables. This allows us to get rid of one database query during a shard resolution.
Now, there are two ways of getting shard configuration based on bucket ranges it belongs to.
First is a simple LINQ query.
var shardDescriptor = cachedDescriptors.Single(
d =>
d.BucketIndexStart <= offset
&& offset <= d.BucketIndexEnd);When the size of the cache is small this is pretty fast (worst case O(n)) but we can do better.
There is a data structure called Range Tree. It is a variant of a binary search tree that allows searching for points that are contained in some ranges stored as keys. It is implemented for .NET and has O(log n + m) working time metric on node query operation.
var shardDescriptor = cachedDescriptors.Query(bucketRangePosition)The construction of this tree is O(n log n) operation but it is done only once so we are perfectly fine with that.
As was stated before, the cache TTL can be days long.
Connection caching
The second optimization to be done here is reducing the actual number of connections that got created for a particular query. Consider a chain of single shard queries. Let’s say we implement two separate repository classes for two different sharded tables residing on one shard.
var data1 = _repository1.Query(shardKeyValue);
var data2 = _repository2.Query(shardKeyValue);
return (data1, data2);Here we will have two separate connections to the same shard resolved as part of executing Query methods for each of the repositories. Unless we want to perform Query operations in parallel this seems redundant.
Let’s add some internal cache for storing connection instances.
internal class NpgsqlConnectionCache : IConnectionCache<NpgsqlDiagnosticConnection>
{
private readonly ConcurrentDictionary<string, DbConnection> _openСonnectionsCache = new();
public NpgsqlDiagnosticConnection GetOrCreateConnection(string connectionString)
{
var key = DbConnectionStringHelper.GetHostPortAndDatabase(connectionString);
DbConnection GetConnection()
{
var connection = _openСonnectionsCache.GetOrAdd(
key,
static (newKey, connectionStringArgument) => new DnConnection(connectionStringArgument),
connectionString);
return connection;
}
var connection = GetConnection();
if (connection.IsDisposed)
{
// means we got connection from cache but it had been disposed in consumer code
_openСonnectionsCache.TryRemove(key, out _);
connection = GetConnection();
}
return connection;
}
}This will allow us to share connection instances between calls to different repositories. Of course there is a problem of removing the connections from this cache upon close and disposal – it has been solved but that’s out of scope of this article.
Inner workings insight
Last but not least thing about any in-application sharding mechanism is diagnostics. We would like to know which shards were resolved from which keys, when caching occurred and so on. Let’s add some instrumentation. We will be using standard DiagnosticListener for providing the way of looking into the library inner workings when it is required.
public class ShardingDiagnosticSource : DiagnosticListener
{
public const string SourceName = "Diagnostics.Sharding";
public const string DataShardResolutionSuccessDiagnosticName = "DataShardResoultion_Success";
internal static ShardingDiagnosticSource Instance { get; } = new();
internal ShardingDiagnosticSource() : base(SourceName)
{ }
}Now we need someone to listen for diagnostics events
public class LoggingShardResolutionDiagnosticListener
{
private readonly ILogger _logger;
private readonly ShardingDiagnosticListenerSettings _settings;
public LoggingShardResolutionDiagnosticListener(
ILogger<LoggingShardResolutionDiagnosticListener> logger,
IOptions<ShardingDiagnosticListenerSettings> options)
{
_settings = options.Value;
_logger = logger;
}
[DiagnosticName(ShardingDiagnosticSource.DataShardResolutionSuccessDiagnosticName)]
public void LogDataShardResolutionSuccess(
string resolvedShardDescription,
bool isResolvedFromCache)
{
if (!_settings.IsLoggingEnabled)
{
return;
}
if (isResolvedFromCache)
{
_logger.Log(
_settings.DiagnosticMessagesLoggerEventLevel,
"Resolved {ResolvedShardDescription} from cache",
resolvedShardDescription);
}
else
{
_logger.Log(
_settings.DiagnosticMessagesLoggerEventLevel,
"Resolved {ResolvedShardDescription}",
resolvedShardDescription);
}
}
}Now simply instrument our code as follows.
if (ShardingDiagnosticSource.Instance.IsEnabled(ShardingDiagnosticSource.DataShardResolutionSuccessDiagnosticName))
{
ShardingDiagnosticSource.Instance.Write(
ShardingDiagnosticSource.DataShardResolutionSuccessDiagnosticName, new{
resolvedShardDescription = ret.DescribeSelf(),
isResolvedFromCache = true
});
}And hook everything together (assuming that we are using a DI container).
DiagnosticListener diagnosticListener = app.ApplicationServices.GetRequiredService<NpgsqlShardingDiagnosticSource>();
var listener = app.ApplicationServices.GetRequiredService<LoggingNpgsqlShardResolutionDiagnosticListener>();
diagnosticListener.SubscribeWithAdapter(listener);This way we will get the diagnostics messages only when consumer actually asked for that.
Limitations
Every solution has it’s limitations and this one is not an exclusion.
- We do not support automatic resharding (yet)
- We do not support multi-shard joins
- We do not support multi-node transactions
The milti-shard transactions or distributed transactions as they are often called is the most complex of the problems one encounter when building a sharding solution. It has been solved by some box solutions – MongoDB, CockroachDB, CitusDB. We are not planning to support it anytime in the future but who knows – maybe we will solve that one someday.
Conclusion
As I’ve said at the beginning, the solution itself is as interesting as the way and research that preceded the implementation itself.
It’s worth noting that a lot of the out-of-the-box sharding solutions use the same logic so I hope it helped you understand their inner workings a bit better.
1 thought on “Home-brew sharding. Creating a bicycle for fun and profit”